| Université Paris 6 Licence d'informatique | Module de Programmation Année 2000-2001 |
|---|
Deux autres représentations également très employées sont la somme de minterms et le produit de maxterms.
a b c f 0 0 0 0 0 0 1 1 0 1 0 1 0 1 1 1 1 0 0 0 1 0 1 1 1 1 0 1 1 1 1 1
Table 1 : Représentation d'une fonction sous forme de table de vérité
| f = |
|
. |
|
.c + |
|
.b. |
|
+ |
|
.b.c + a. |
|
.c + a.b. |
|
+ a.b.c |
| f = |
|
.c + b |
| f = (a + b + c).( |
|
+ b + c) |
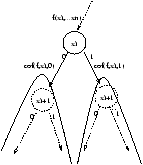
| f = xi . cof(f,xi,1) + |
|
. cof(f,xi,0) |
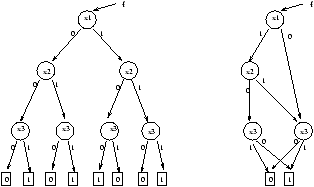
Cette représentation arborescente a une taille exponentielle avec l'arité de la fonction représentée, de fait, elle est inexploitable en l'état. Par contre, elle présente une très forte potentialité de réduction, ce qui la rend efficace dans la plupart des cas.
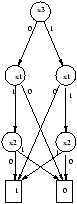
Un résultat très important concernant ces diagrammes de décision binaire réduits et ordonnés est leur canonicité : Soient deux fonctions booléennes f et g de Bn -> B.
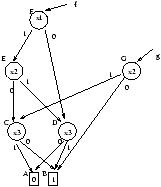
La table de partage correspondant à cette situation est représentée ci-après.
noeud index FilsZ FilsU A - - - B - - - C 3 B A D 3 A B E 2 C D F 1 D E G 2 B C
Table 2 : Table de partage des BDD de la figure 3
| not f | = |
|
||||||
| = |
|
| f op g | = |
|
|||||||||||
| = |
|
| exists(f,x) | = | cof(f,x,1) + cof(f,x,0) |
| forall(f,x) | = | cof(f,x,1) . cof(f,x,0) |
| subst(f,x,g) = g . cof(f,x,1) + |
|
. cof(f,x,0) |
syntaxe_abstraite.ml : la définition de la syntaxe
abstraite représentant les expressions booléennes saisies au
clavier.
<expr> ::= <nom>
| <expr> + <expr>
| <expr> * <expr>
| ! <expr>
| <expr> = <expr>
| <expr> => <expr>
| ( <expr> )
| exists <nom>. <expr>
| forall <nom>. <expr>
| <expr> [<nom> \ <expr>]
Un <nom> désigne une suite ininterrompue de caractères
représentant un nom de variable. Les symboles +, * et !
désignent respectivement la conjonction, la disjonction et la
complémentation. = et => désignent respectivement
l'égalité et l'implication. exists et forall
désignent les quantifications existentielle et universelle. La
dernière ligne indique la syntaxe de la substitution : substituer,
dans <expr> de gauche, à la variable <nom>,
l'expression <expr> de droite.syntaxe_abstraite.ml.read_expr_string et
read_expr_on_input_channel (définies dans le fichier
main.ml vous permettent de construire un arbre de syntaxe
abstraite à partir d'une expression représentée par une chaîne de
caractères ou saisie au clavier. read_expr_string "0" puis read_expr_string "x",
puis de read_expr_string "(x + y) * exists v. (t \ !v)"make_bdd expr qui retourne le BDD
(ordonné) de l'expression représentée par un arbre de
syntaxe abstraite.
print_bdd b qui affiche soit le
BDD b complet, soit uniquement les valuations des
variables pour lesquelles la fonction représentée par
b est vraie, soit uniquement les valuations des
variables pour lesquelles la fonction représentée par
b est fausse.
find_in_cache_table et
add_in_cache_table associées à cette table.
type descr_bdd = Noeud of int * bdd * bdd | Feuille of bool
and bdd = {id = int; noeud = descr_bdd; mutable marque = bool;;
find_in_ite_table et
add_in_ite_table associées.
(indication : hacher sur le triplet :
(index, identifiant(b1), identifiant(b2)) et non sur
(index, b1, b2)).
count_bdd qui compte le nombre
de noeuds d'un BDD réduit.
make_bdd, et enfin à imprimer les
solutions. | vi,j Þ |
|
|
| vi,j Þ |
|
|
| vi,j Þ |
|
|
| vi,j Þ |
|
|
Ce document a été traduit de LATEX par HEVEA.